
Appearance
GPU选型
目前平台提供的GPU算力
| 显卡 | 显存(GB) | 内存(GB/卡) | CPU配置 | 存储 | 操作平台 |
|---|---|---|---|---|---|
| RTX 4090D | 24 | 100 | 2.6GHz 18Core | 100G系统盘 | Linux |
| RTX 4090 | 48 | 120 | 3.7GHz 32Core | 100G系统盘 | Linux |
| RTX 4090 | 24 | 90 | 2.5GHz 14Core | 30G系统盘 | Linux |
| RTX 3090 | 24 | 60 | 2.5GHz 14Core | 30G系统盘 | Linux |
资源分配规则
比例分配机制
CPU与内存按购买的GPU数量成比例分配。产品服务显示的CPU和内存均为每张GPU分配的CPU和内存,如果租用两块GPU,那么CPU和内存就x2。
GPU独占性
每块GPU由实例独占使用,无资源共享问题。
选择CPU
CPU非常重要! 尽管CPU并不直接参与深度学习模型计算,但CPU需要提供大于模型训练吞吐的数据处理能力。
性能说明
分配更多核心通常不会显著提升性能,此时瓶颈通常源于:
- Python多进程切换开销
- 数据通信开销(如PyTorch DataLoader)
选择GPU
目前平台上提供的4种规格的GPU型号,后续会陆续推出其它型号的GPU供客户选择。
选择内存
⚠️严格内存限制
实例内存使用存在硬性上限,超出限制将直接终止进程,不同于本地电脑的虚拟内存机制。
🚫 危险操作预警
内存超限会导致实例自动重置,系统盘所有数据将被清空。
✅解决方案
- 预估内存需求,选择更高配置主机
- 多GPU实例可扩展总内存容量
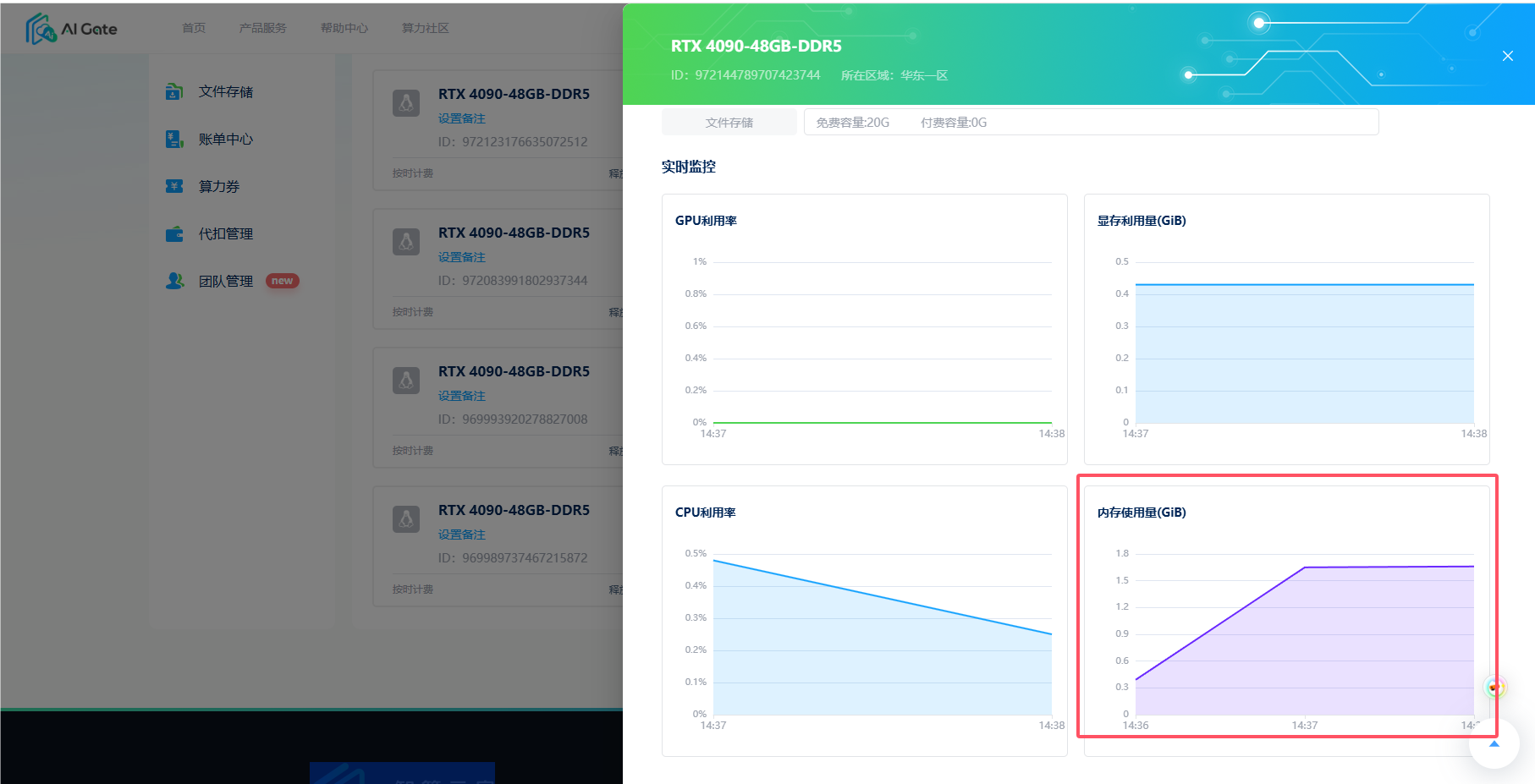
- 实时通过控制台 -> 实例管理 ->「运行详情」查看内存占用
🌟 高手秘籍
训练前通过小规模数据测试内存消耗峰值,预留20%安全余量。
🚫避坑指南
- 务必检查CUDA版本与框架兼容性!
- 内存监控预警设为90%,避免进程意外终止。
- 训练过程中如果显存爆了可以尝试释放当前实例,租用多卡实例。